Garbage collection
JVM manage heap memory itself (compared by C++ where it is user managed). So main task objective of GC is
find unused objects in memory and remove it with hole filling. There are four main GC algorithms:
serial collector, throughput collector, concurrent collector and G1 collector. We have tradeoff between
memory and cpu consumption in limitation of cpu core count.
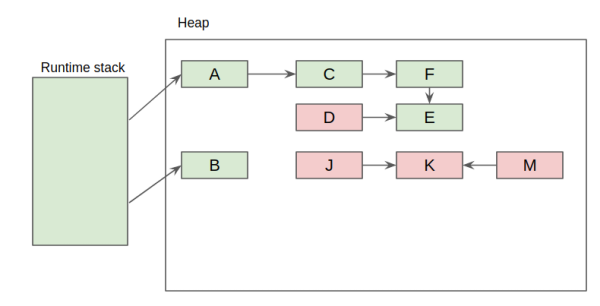
GC removes objects from heap if no links from runtime stack. Main hypnosis of GC is weak hypnosis of
generations: most objects a short living and old objects rarely links to new one. So we can split memory
to generations: young & old generations. And we can collect objects in young separately of old. Trip from
young to old can be defined by some age.
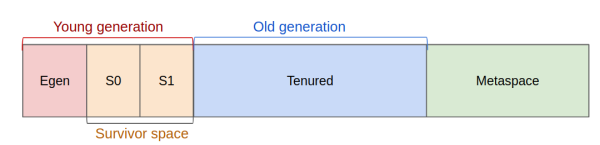
In the same time we can split young generation into some sub regions. Egen - new objects will be allocated
here. And two survivor spaces: s0 & s1. When the are not enough space in egen we start small collection:
copy all objects from eden to s0 and someone from s1 to old generation. So in s1 we can find objects who
survived after at least once gc.
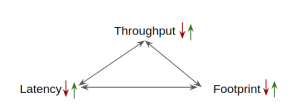
GC Performance metrics
- Throughput
- Predictable (latency)
- Footprint (memory usage)
Algorithms
Serial GC
This collector is default for single-processor machines. We stop all application threads (GC pause) during
full GC.
Throughput collector
This collector is default for mutli-CPU machines with 64-bit JVM. We use multiple threads to collect the
young generation. The throughput collector stops all application threads during minor and full GC.
CMS collector
This collector eliminate the long pauses in full GC cycles. We stop all application threads during a minor
GC, it also performs with multiple threads.
G1 collector
This collector designed to process large heaps (4GB plus) with minimal pauses. It divides the heap into a
regions. G1 clean up objects from th old generation by copying from one region into another.
Tip You can call full GC manually using System.gc() when
you known that is right time to wait.
Tuning
Heap size. We can control heap size using -Xms{N} (initial) and -Xmx{N}
(max).
Generation sizes. We can control ratio of young to old generation by -XX:NewRatio=N,
young generation size by -XX:NewSize=N (initial) and -XX:MaxNewSize=N (max).
Metaspace. JVM loads classes and saves their meta data into metaspace (Java 8, in Java 7 - permanent
generation) in separate heap space.
This information contains only JVM specific meta data (not classes). We can prevent expensive resize of
metaspace using large initial metaspace size.