
Introduction. When we want to store we meet the trade-off between flexibility and storage efficiency. Old
school
formats like csv, json and xml let you have high flexibility with human readable features as a benefit but at
the same time it is not so good when you have a lot of data. For big data processing where data is stored in an
archive way we can use binary formats with storage tricks like indexes and compression. So we can not ignore
file formats like Apache Parquet, Apache Iceberg, Apache Avro, Apache Orc, etc. In this post we will go deeper
to Apache Parquet format.
Storage layout. The first trick is the physical storage layout. At the logical level we work with tables:
rows
with a fixed set of columns. But we can store tables at disk in three ways:
- Row wise. Store each row sequentially. We store row 1 with all row’s column values. For example: [(ROW_1 COL_1), (ROW_1 COL_2), (ROW_2 COL_1), …]. This method used by CSV, JSON and XML file formats.
- Columnar. Store each column sequentially: values of each column grouped in sequancies. For example: [(ROW_1 COL_1), (ROW_2 COL_1), …]. This method allows to navigate over wide tables (a lot of column in table).
- Hybrid. Split table in into chunks horizontally and store by column.

For OLTP (a lot of small operations involving whole rows) it is better to use a row wide method but for OLAP
(few large operations involving a subset of columns) better to use hybrid format. For this reason relation
databases like PostgreSQL / MySQL prefer row wise format and feel bad with wide columns table and analytical
databases like Clickhouse / Vertica prefer hybrid format.
Parquet like archive storage format use Hybrid physical storage layout.
Format in files level. In disk parquet usually splitted into multiple files in one or multiple sub directories. Where each sub directory can be used for partition needs.
Format in file level. Data organized in each file with fixed schema. File contains:
Format in files level. In disk parquet usually splitted into multiple files in one or multiple sub directories. Where each sub directory can be used for partition needs.
Format in file level. Data organized in each file with fixed schema. File contains:
- Row groups (default size is 128MB like Hadoop file chunk).
- Column chunks
- Pages (default 1MB)
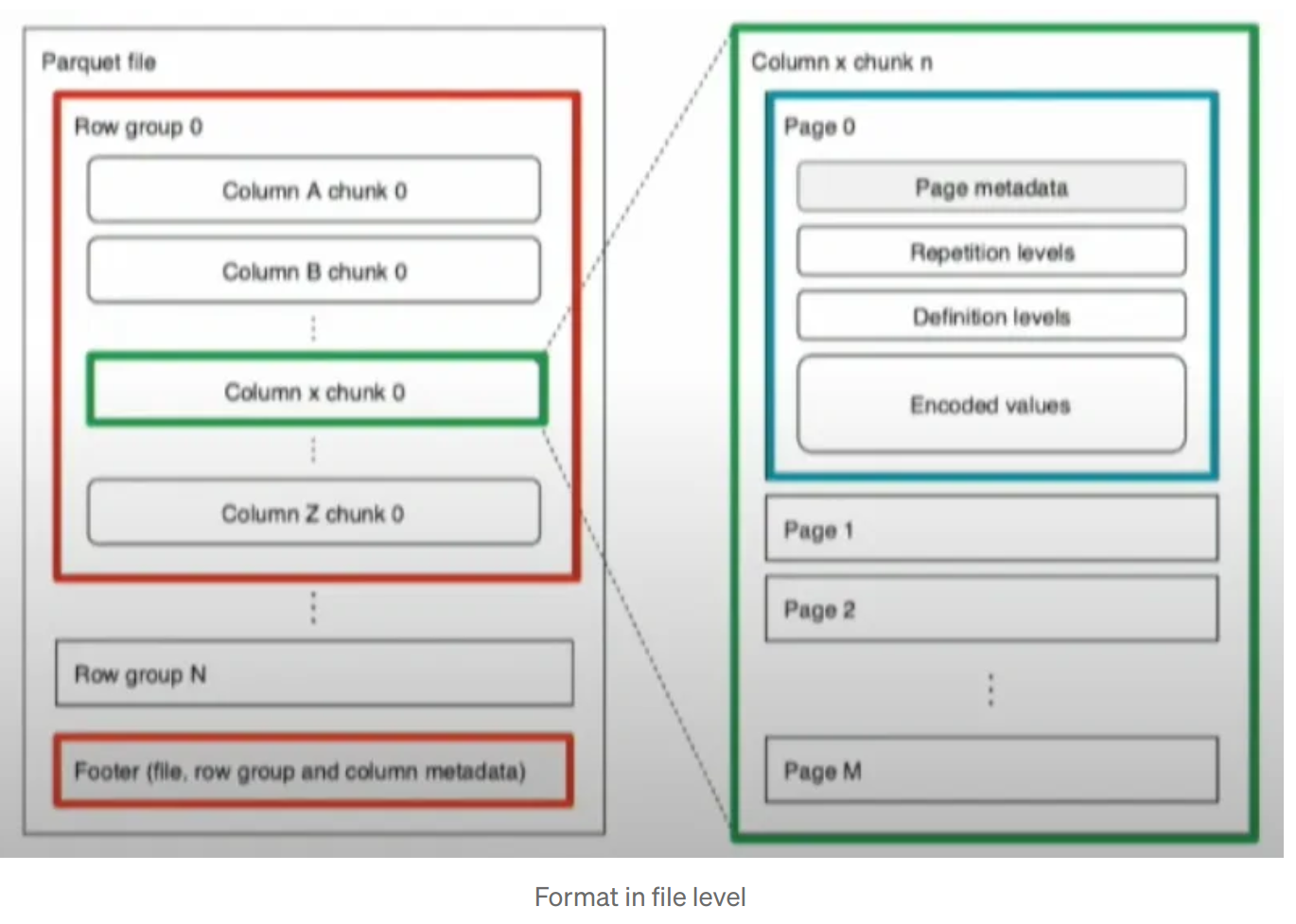
Metadata stored in page and file level. Remember that if the file metadata is corrupt, the file is lost. If the
column metadata is corrupt, that column chunk is lost (but column chunks for this column in other row groups are
okay). If a page header is corrupt, the remaining pages in that chunk are lost. If the data within a page is
corrupt, that page is lost. The file will be more resilient to corruption with smaller row groups.
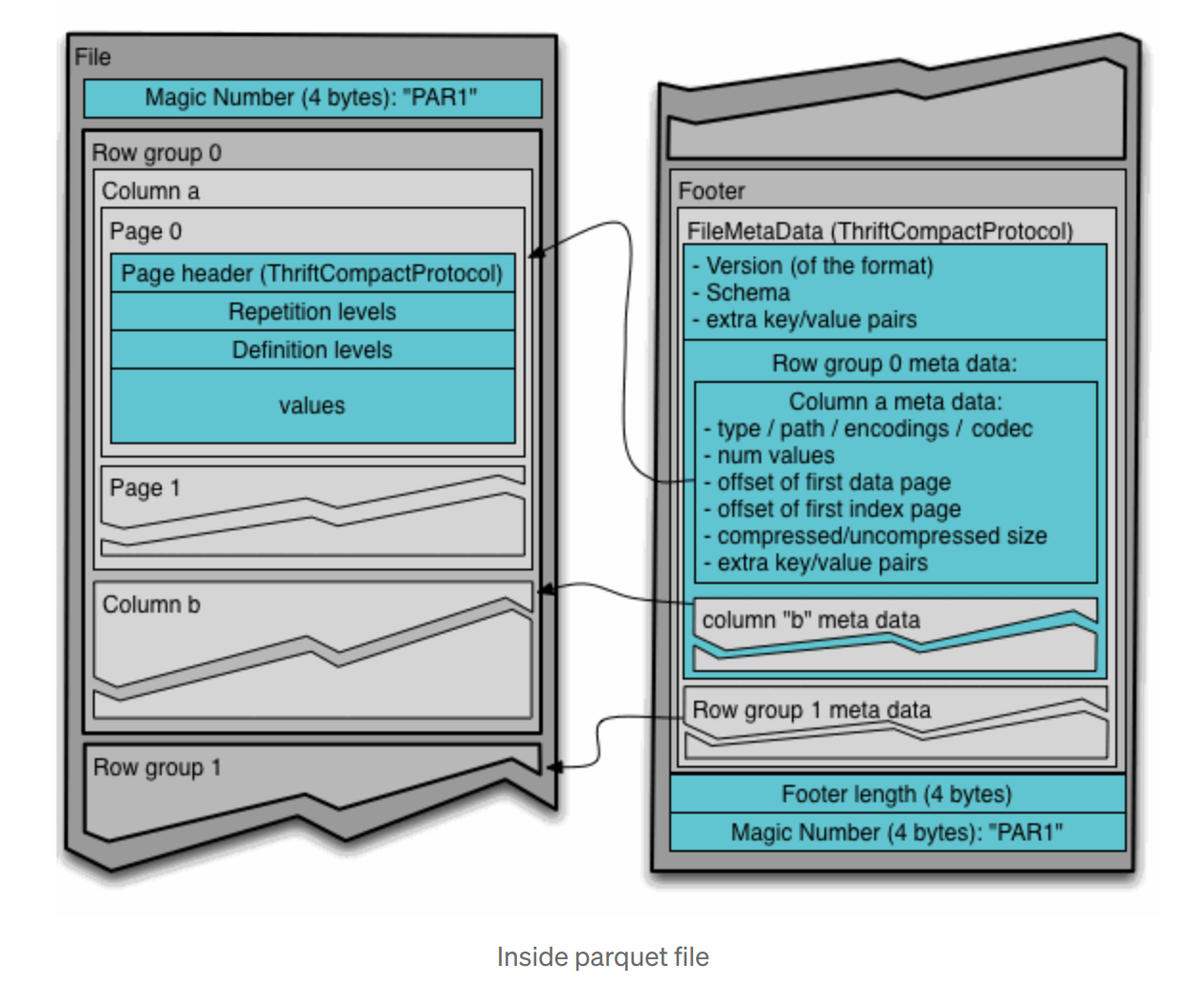
There are three types of metadata: file metadata, column (chunk) metadata and page header metadata. All Apache
Thrift structures are serialized using the TCompactProtocol
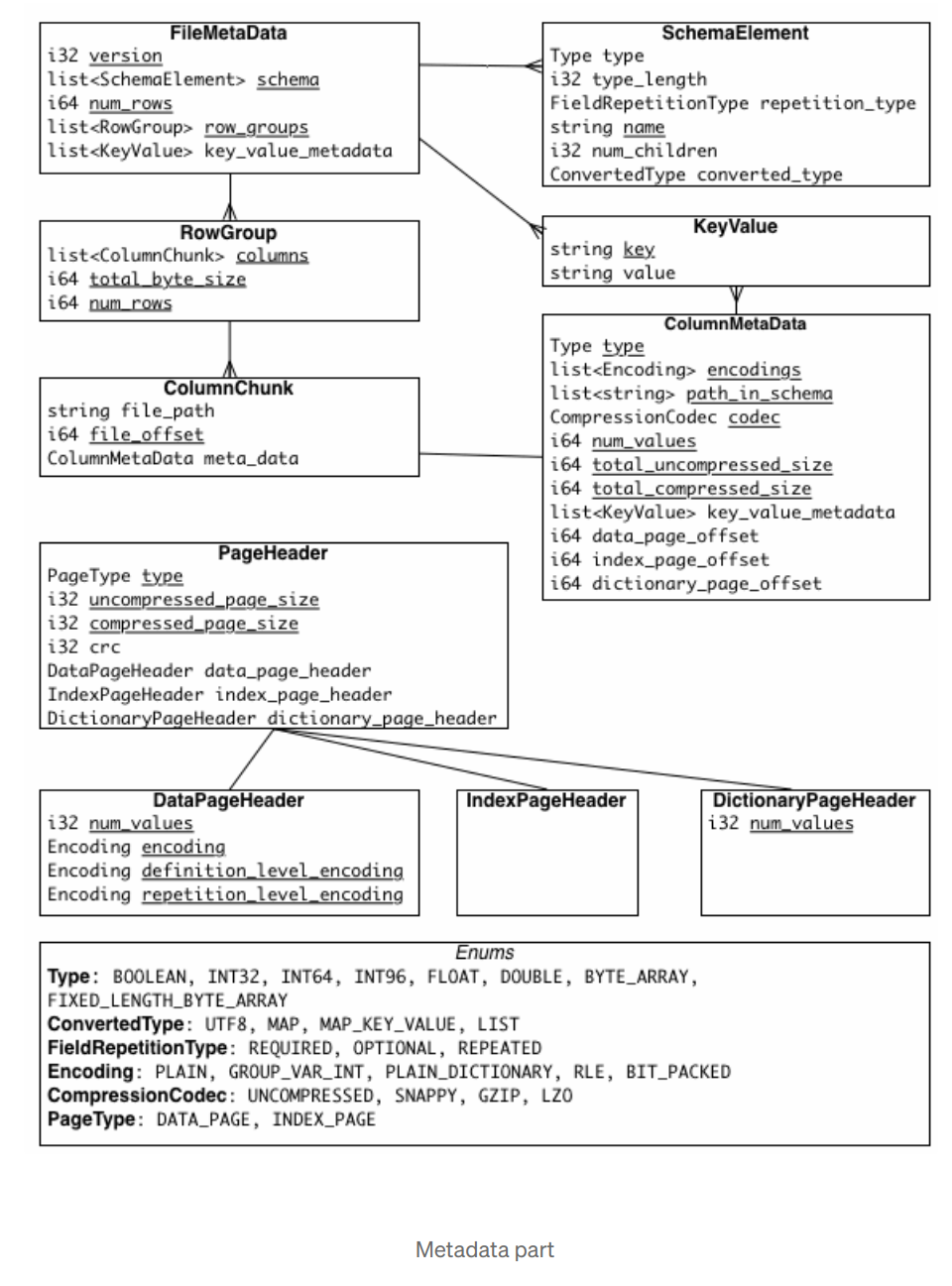
The main advantage of metadata is quick navigation over chunks without lookup into each one. For example we can
do predicate push down in case where we want to filter column > X using metadata.

Encoding. Another optimization is dictionary encoding that detects small number of unique values and
compress
that using dictionary. In extension of that parquet use bit backing technique that allows to store small
integers packed into same space. RLE (Run-length encoding) optimize storage of multiple occurrences of the same
value, a single value is stored once along with the number of occurrences.
Compression. Apache Parquet allows to choose compression algorithm of entire pages. Configuration
spark.sql.parquet.compression.codec can be none, uncompressed, snappy, gzip, lzo, brotli, lz4, zstd. Note that
`zstd` requires `ZStandardCodec` to be installed before Hadoop 2.9.0, `brotli` requires `BrotliCodec` to be
installed.
Partitioning. In this way we can partition by date (YYYY-MM-DD) and open only target files. Use
df.write.partitionBy("col1", "col2", ...).parquet(filename) for partitioning.
Parquet for streaming. Parquet is created for archive storage and has metadata overhead that means that parquet
is not a good choice for streaming. Prefer Apache Avro that uses row based storage schema without huge metadata
overhead.
Value Types. Supported value types:
- BOOLEAN: 1 bit boolean
- INT32: 32 bit signed ints
- INT64: 64 bit signed ints
- INT96: 96 bit signed ints (spark use that format for storing timestamp, use flag spark.sql.parquet.int96AsTimestamp tells Spark SQL to interpret INT96 data as a timestamp to provide compatibility with these systems)
- FLOAT: IEEE 32-bit floating point values
- DOUBLE: IEEE 64-bit floating point values
- BYTE_ARRAY: arbitrarily long byte arrays.
View parquet file data. Use parquet-tools with cat for scan file like parquet-tools cat --json
<file>. Also parquet-tools meta <part> shows a file metadata.
General tips or Best practices for Parquet (not only) like a summary.
- Avoid small files
- Avoid large files
- Use right partition key
- Use denormalization and pre compute : replace evaluation / joins with simple filter in future
- Use Apache Parquet for archive storage and Apache Avro for streaming
References:
- https://parquet.apache.org/docs/
- https://www.youtube.com/watch?v=1j8SdS7s_NY
- https://www.youtube.com/watch?v=rVC9F1y38oU
- https://www.youtube.com/watch?v=_0Wpwj_gvzg
