In Apache Spark, Spark Shuffle describes the procedure in between reduce task and map task. Shuffling refers to the shuffle of data given. This operation is considered the costliest. Parallelising effectively of the spark shuffle operation gives performance output as good for spark jobs.
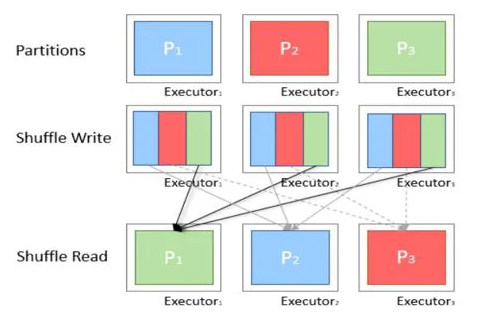
Operations that trigger shuffling
- Repartition transformations (repartition, coalesce, partitionBy)
- Many key-based operations (reduceByKey, foldByKey, combineByKey, groupByKey, cogroup, join, sortByKey, lookup)
In depth
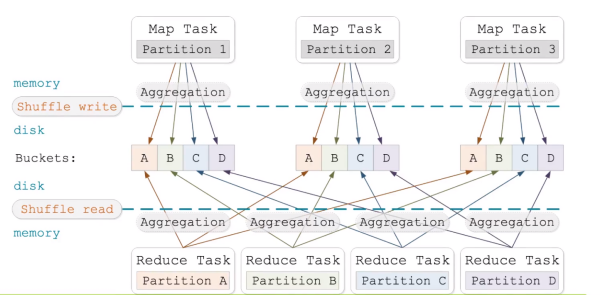
Sort-based shuffling
- Generally more efficient
- Default in Spark 1.2+
- Writes 2*M files
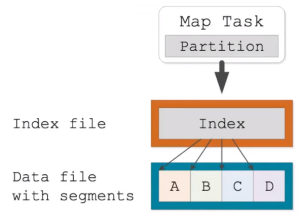
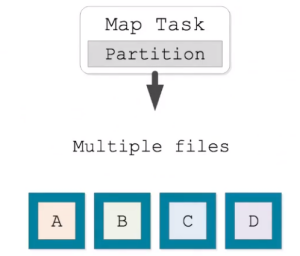
Hash-based shuffling
- Generally less efficient
- Default in Spark before 1.2
- Writes M*R files
Tungsten sort
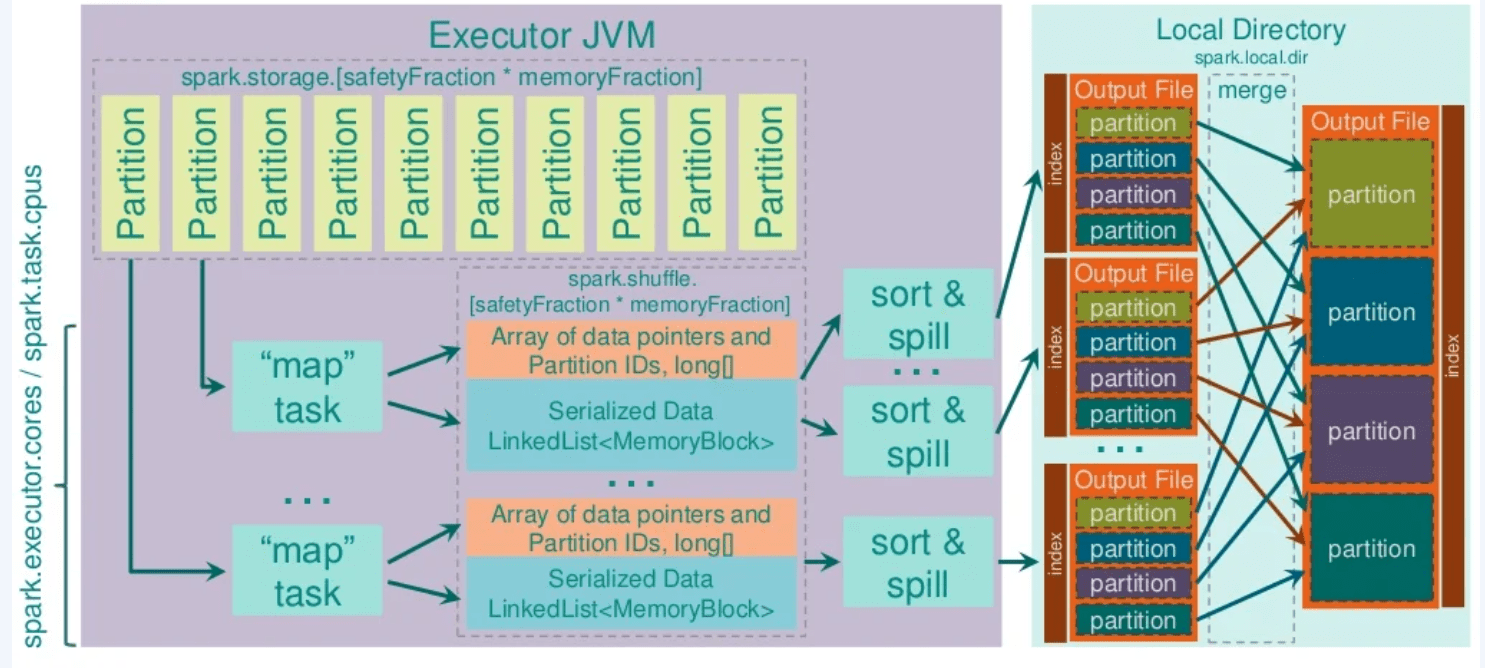
Cost factors
- Disk IO
- Network traffic
- Partitioning
- External sorting
- Serialization/deserialization
- Data compression
Way to optimize
- Control partitioning to avoid re-shuffling
- Take advantage of aggregation when possible
- Choose appropriate application properties
Related articles: