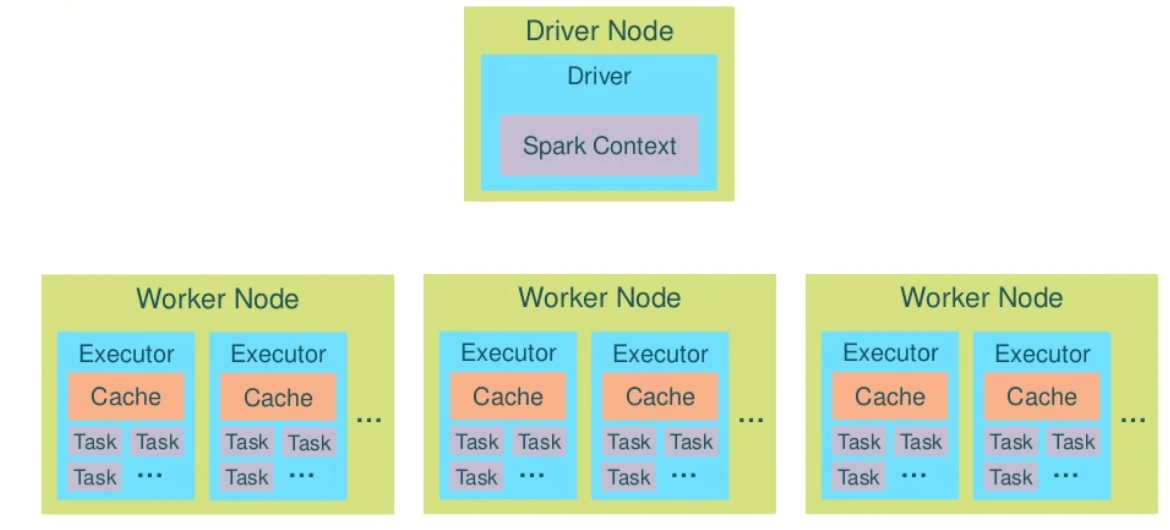
Spark Cluster operate with drivers and executors.
Driver is entry point of the Spark Shell (Scala, Python or R). It is the place where SparkContext is created. Driver translates RDD into execution graph and split graph into stages. This program schedules tasks and controls their execution and stores metadata about all the RDDs and their partitions.
Executor stores the data in cache in JVM heap or on HDDs. This program reads data from external sources, performs all the data processing and writes to external sources.
Lets decompose application.
- Application is a single instance of SparkContext that stores some data processing logic and can schedule series of jobs, sequentially or in parallel.
- Job is complete set of transformations on RDD that finishes with action or data saving, triggered by the driver application.
- Stage is set of transformations that can be pipelined and executed by a single independent worker. Usually it is app the transformations between "read", "shuffle", "action", "save".
- Task is execution of the stage on a single data partition. Basic unit of scheduling.
Related articles: