Agenda
Various storage solutions are available in AWS Cloud, which differ primarily in the level of automation from the cloud provider: from a block disk given under full user control to Key-Value storage with a programmable object lifecycle and access characteristics. It should be noted that each type of storage is suitable for its workload.
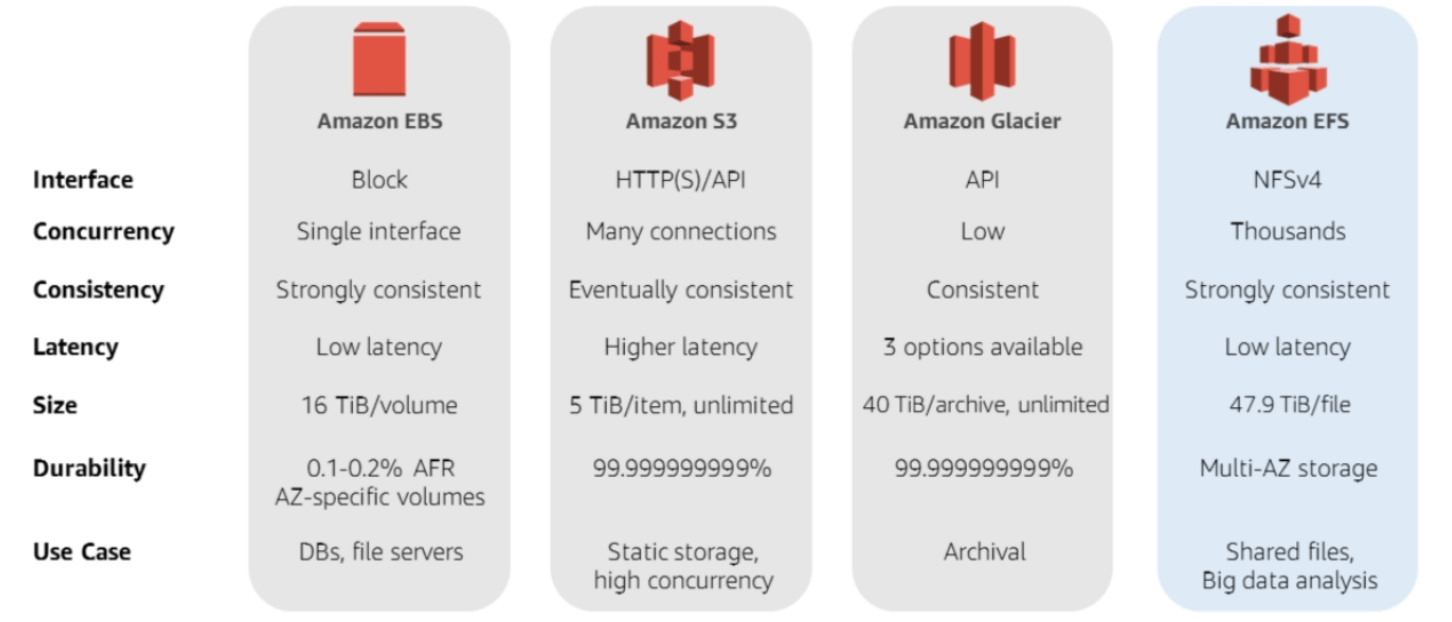
This note covers only general purpose storages: EBS, EFS, S3, Glacer. For storing structured or semi-structured data, we recommend referring to database.
Introduction
Data locality. Before diving into storage types, let's take a look at the basics of data locality in AWS Cloud. All data centers are divided into regions - the physical location where our data centers are located. A group of interconnected data centers is called an Availability Zone. Each AWS Region is made up of multiple isolated and physically separate Availability Zones in a single geographic area. An Availability Zone is one or more data centers with redundant power supply, networking, and connectivity in the AWS Region.
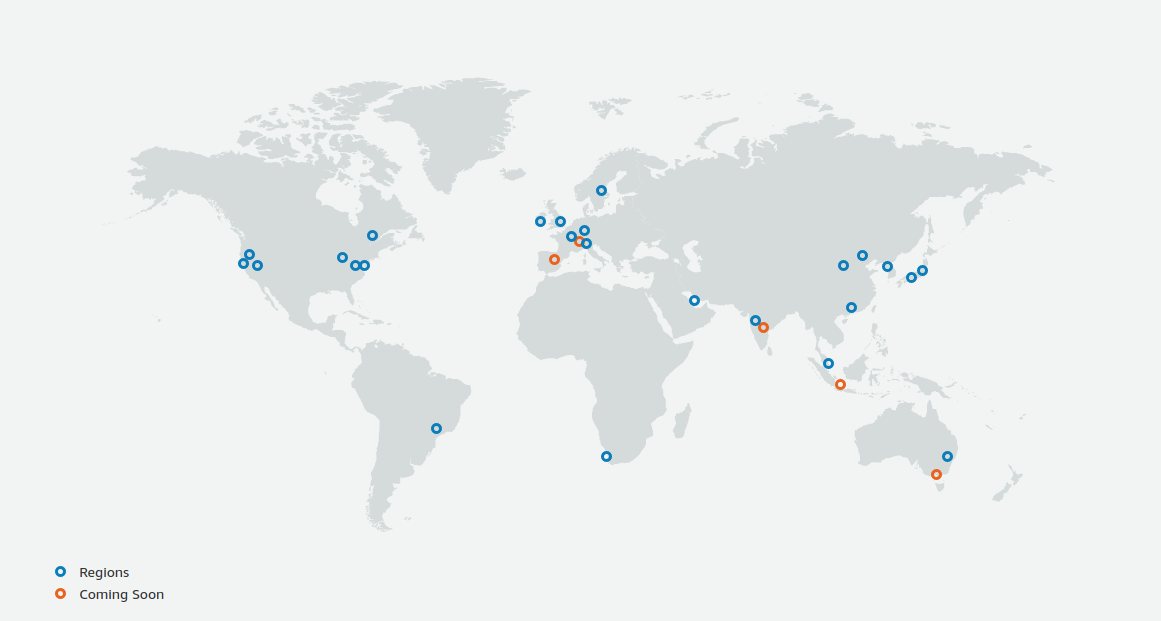
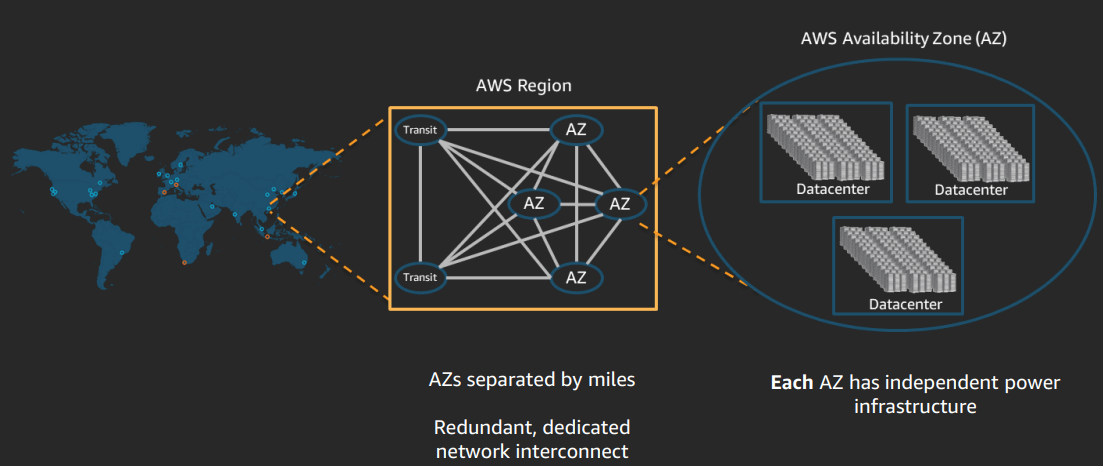
The hierarchy is as follows: different regions> one region> one availability zone (AZ). Every time we want to increase the availability of our service, in the event of a data center failure, we are moving towards decreasing locality. The highest level of fault tolerance that can be obtained within this model is multi region, which is exactly what Netflix did after the failure of one of the regions.
Related: Story by Netflix A Closer Look at the Christmas Eve Outage .
Access pattern. When considering different types of storage, it is important to take into account not only the size of files, but also the access pattern: how often the data is accessed, what is the ratio between read and write operations, how elastic the storage should be (maximum available space).
Price. Taking into account the access pattern, you can calculate the cost of a particular solution. It is worth noting here that more AWS Managed services allow you to flexibly rate individual files. For example, files of an archive type, access to which is rare or exclusive, can be converted to an archive type of storage: storing such data is much cheaper than a standard storage class. https://calculator.aws/#/
Access control. Depending on the type of storage, the access restriction options vary: from POSIX flags to object-level management with AWS IAM and the ability to maintain an independent access log (AWS Trails).
Availability. Availability usually refers to both the ability to obtain data and the risk of data loss. Increased availability increases storage costs through redundant storage of data by locating in multiple AZs or multiple regions. It is also worth considering the speed of data access: it can vary from a few milliseconds to hours (in the case of S3 Glacer Deep Archive).

Storage types. Storage in AWS can be divided into Block (EBS, like classic hard drives), File (EFS, like NFS), Object (S3, like Key-Value file storage).
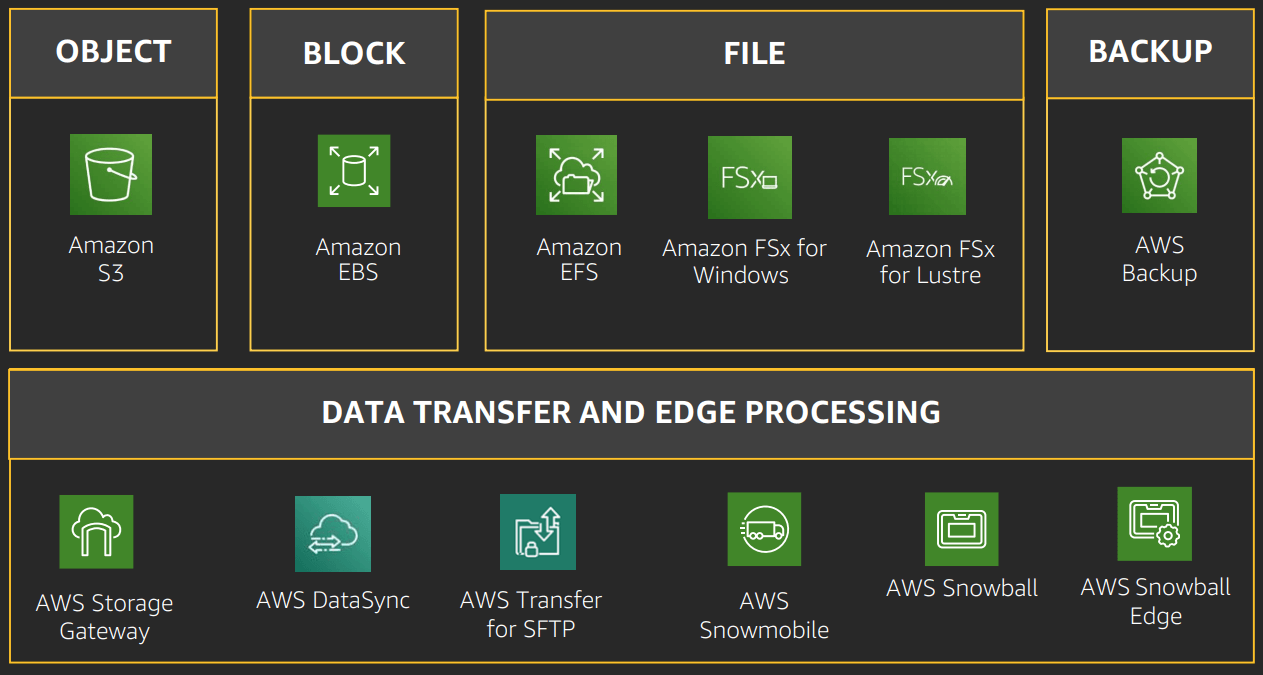
EBS
EBS (Elastic Block Store) is like a regular hard drive and is mounted on the file system. To access this type of data, an EC2 (VM) is required in the same Availability Zone as the EBS volume. For Provisioned IOPS SSD drives, you can use a shared drive for multiple EC2 Instances (VMs). The maximum size of a single disk is 16 TiB, if you need more space, connect an additional disk.
All files on a disk have a single storage class, which is determined by the type of disk:
- SSD
- General Purpose SSD
- Provisioned IOPS SSD
- HDD
- Cold HDD
- Throughput Optimized HDD
- Previous generation (Magnetic)
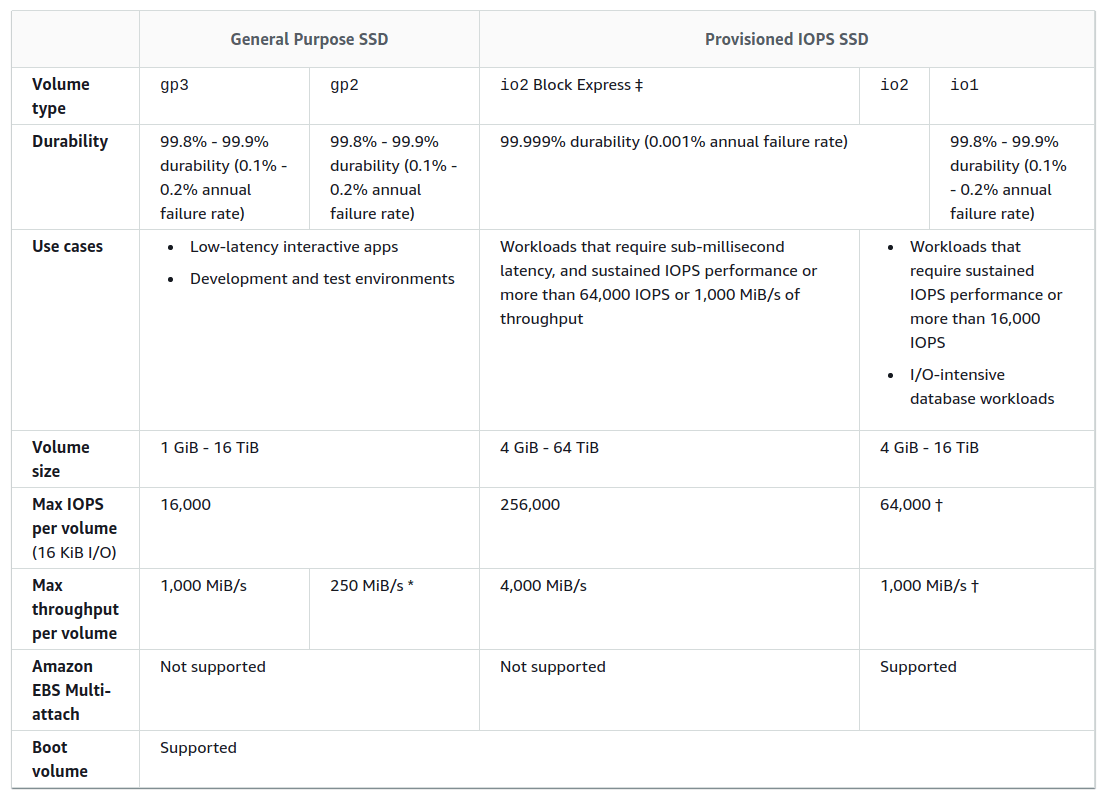
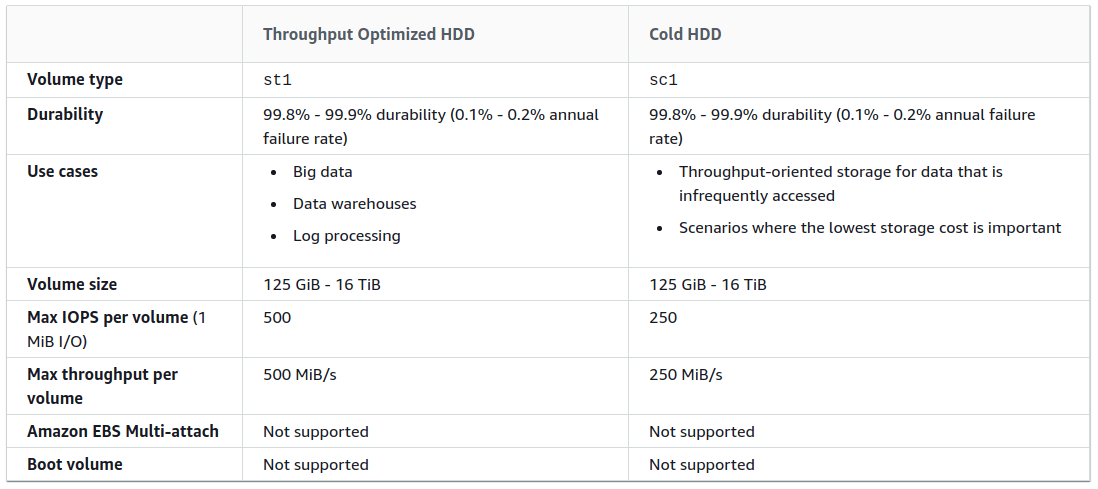
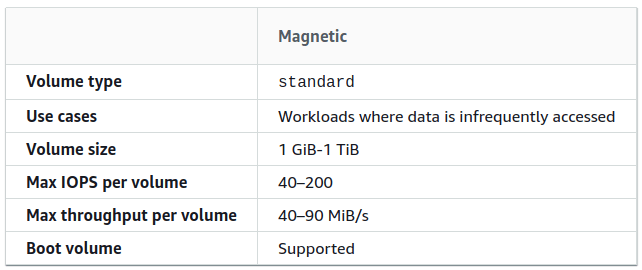
This type of disk supports encryption at all stages: data transfer, storage, archiving.
Archived copies (Snapshots). Supports automatic creation of scheduled backups, as well as copying them to separate regions to increase storage reliability.
An important feature of using this type of disk in the context of EC2 Instances (VM): they are not automatically deleted after the EC2 Instance is uninstalled. After removing the VM, you need to uninstall Volumes separately.
Summary. This type of storage is closest to the classical data storage approach. The user has a great deal of independence, receiving in return the speed and ease of integration with classic applications focused on working with a hard drive. The downside is the need for manual management, the limited size of each disk, and the lack of built-in data replication.
Best for: Most workloads with fast access speeds and application fault tolerance (e.g. DBMS).
Not for: big data storage.
EFS
EFS (Elastic File System) is most similar to a network drive (NFS), it supports both placement in one Availability Zone (One Zone) and in several (Regional).
The file storage type is specific to each EFS instance and varies in the following ranges:
- General Purpose - Ideal for latency-sensitive use cases, like web serving environments and content management systems
- Max I / O - Scale to higher levels of aggregate throughput and operations per second (Max I / O performance mode is not available for file systems using One Zone storage classes.)
Likewise, encryption is supported with EBS.
To save money, it is proposed to automatically move unused files to the Infrequent Access storage class.
Summary. This type of storage is intermediate between EBS (focused on user management) and S3 (a service for managing binary objects), before using instances of this type, be sure to evaluate its cost, perhaps S3Fuse (mount s3 to file system) will be more preferable for you in in terms of price.
Best for: filing documents.
Not for: large raw data.
S3
S3 (Simple Storage Service) is a service for storing binary data. A data storage unit is an Object located in a Bucket, which in turn is located in one of the AWS regions. At the same time, access to the bucket is not limited by the region, but rather affects the speed and price of data access.
It supports file versioning (S3 Version), as well as blocking the deletion of files for a specified period (S3 Object Lock).
The storage class is defined at the object level, so files in the same bucket can have a different storage class. As a result, have different storage and access rates.
- S3 Standard
- S3 Intelligent Tiering
- S3 Standard IA
- S3 One Zone IA
- S3 Glacer
- S3 Glacer Deep Archive
Glacer is a special class of data storage. It is designed for archival data storage with ultra-low data retrieval rates. This is offset by the storage cost, which reaches 1 USD per TiB per month.

It is recommended to use s3 Standard by default and based on data usage analytics move files in automatic or semi-automatic mode to other classes. The Lifecycle Manager can help with this.
Note that the use of Intelligent Tiering is advisable in the case of large files, billing is per file.


[ALERT] Be sure to configure Lifecycle to delete temporary files multipart uploads (Delete expired delete markers or incomplete multipart uploads). This is often where unexpected storage costs are hidden, which are not visible in the overall usage analysis.
For operations on a large amount of data, it is proposed to use s3 Batch Operations.

Events. Based on events, it is recommended to implement a pipeline for processing new data: instead of scanning the list of bucket objects, it is proposed to use events (for example, a new object was created), on the basis of which to work with specific files. Events can be consumed by
- Lambda
- SNS topic
- SQS queue
Use CloudTrail or Server access logging to audit data access.
Hosting of static files. S3 can be used as hosting for static files by pre-configuring CloudFront as a caching revers proxy.
Summary. S3 is a full-fledged data storage service, while the user defines data management policies through the API. The flexible access control model and storage class make S3 a good option for storing source files that do not require instant access.
Best for: media / raw files
Not for: storing DBMS hot files
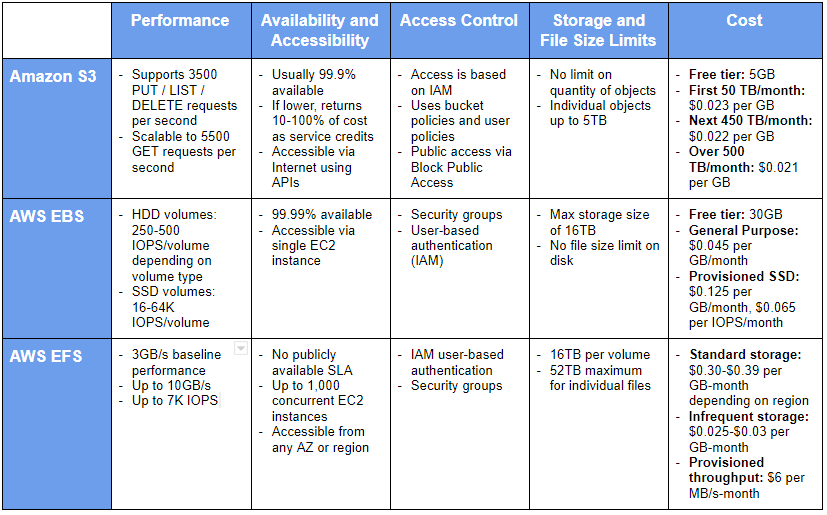
Summary
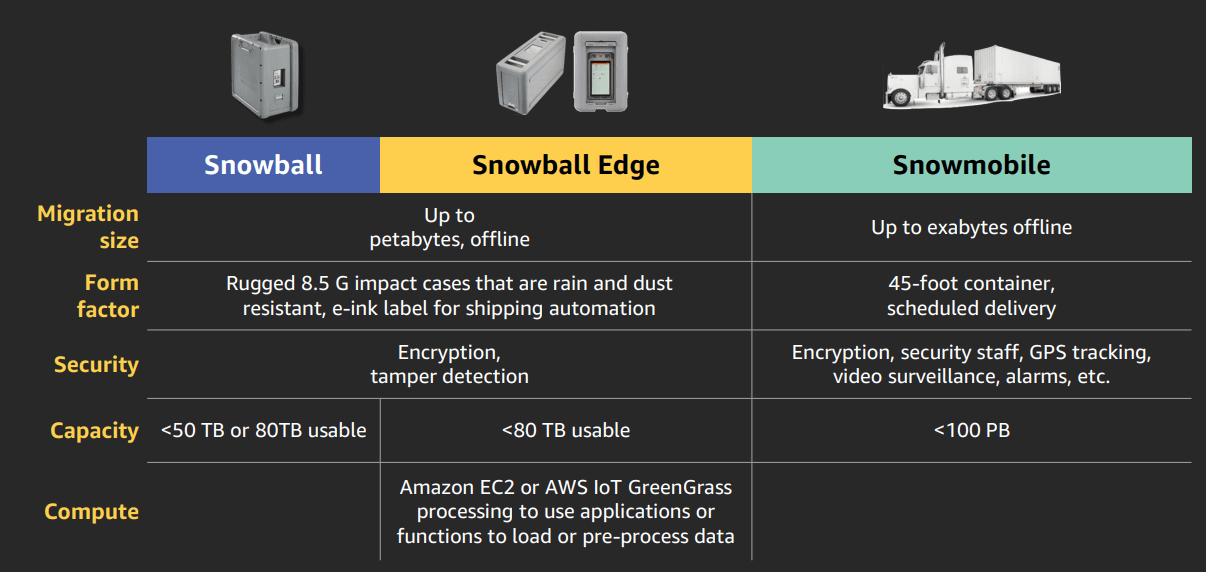
(Bonus) Snow family
Limited online data transfer options due to:
- Connectivity limitations
- Bandwidth constraints
- Restrictions on protocol support
- Legacy environments
- Data properties and usage patterns
- Data collected in remote/ austere locations