You could also describe Spark as a distributed, data processing engine for batch and streaming modes featuring SQL queries, graph processing, and machine learning.
In contrast to Hadoop’s two-stage disk-based MapReduce computation engine, Spark's multi-stage (mostly) in-memory computing engine allows for running most computations in memory, and hence most of the time provides better performance for certain applications, e.g. iterative algorithms or interactive data mining
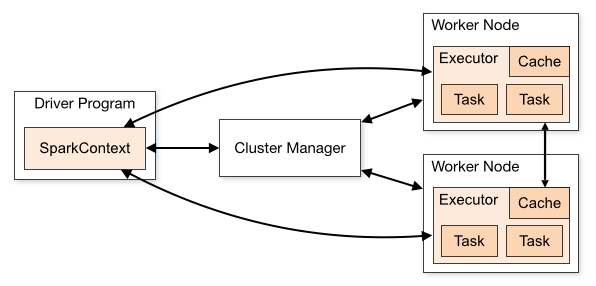
Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in your main program (called the driver program).
Specifically, to run on a cluster, the SparkContext can connect to several types of cluster managers (either Spark’s own standalone cluster manager, Mesos or YARN), which allocate resources across applications. Once connected, Spark acquires executors on nodes in the cluster, which are processes that run computations and store data for your application. Next, it sends your application code (defined by JAR or Python files passed to SparkContext) to the executors. Finally, SparkContext sends tasks to the executors to run.
Limitations
- No real time processing support (Lattency vs Throutput)
- Expensive
- Small files problems
- Manual optimization
- Back pressure handling
Data containers
- RDD (Resilient Distributed Datasets)
- Dataframe
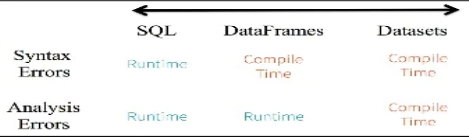
- Datasets (handle semantic error during compilation)
Transformations
In Spark, the core data structures are immutable meaning they cannot be changed once created. This might seem like a strange concept at first, if you cannot change it, how are you supposed to use it? In order to “change” a DataFrame you will have to instruct Spark how you would like to modify the DataFrame you have into the one that you want. These instructions are called transformations. Transformations are the core of how you will be expressing your business logic using Spark. There are two types of transformations, those that specify narrow dependencies and those that specify wide dependencies.
Narrow Dependencies Transformations consisting of narrow dependencies [we’ll call them narrow transformations] are those where each input partition will contribute to only one output partition.
Wide Dependencies A wide dependency [or wide transformation] style transformation will have input partitions contributing to many output partitions. You will often hear this referred to as a shuffle where Spark will exchange partitions across the cluster. With narrow transformations, Spark will automatically perform an operation called pipelining on narrow dependencies, this means that if we specify multiple filters on DataFrames they’ll all be performed in-memory. The same cannot be said for shuffles. When we perform a shuffle, Spark will write the results to disk. You’ll see lots of talks about shuffle optimization across the web because it’s an important topic but for now all you need to understand are that there are two kinds of transformations.
Partitioning
The partition columns should be used frequently in queries for filtering and should have a small range of values with enough corresponding data to distribute the files in the directories. You want to avoid too many small files, which make scans less efficient with excessive parallelism. You also want to avoid having too few large files, which can hurt parallelism.
Coalesce and Repartition Before or when writing a DataFrame, you can use dataframe.coalesce(N) to reduce the number of partitions in a DataFrame, without shuffling, or df.repartition(N) to reorder and either increase or decrease the number of partitions with shuffling data across the network to achieve even load balancing.
df.write.format("parquet")
.repartition(13)
.partitionBy("src")
.option("path", "/user/mapr/data/flights")
.saveAsTable("flights")Bucketing Bucketing is another data organization technique that groups data with the same bucket value across a fixed number of “buckets.” This can improve performance in wide transformations and joins by avoiding “shuffles.” With wide transformation shuffles, data is sent across the network to other nodes and written to disk, causing network and disk I/O and making the shuffle a costly operation. Below is a shuffle caused by a df.groupBy("carrier").count; if this dataset were bucketed by “carrier,” then the shuffle could be avoided.
Bucketing is similar to partitioning, but partitioning creates a directory for each partition, whereas bucketing distributes data across a fixed number of buckets by a hash on the bucket value. Tables can be bucketed on more than one value and bucketing can be used with or without partitioning.
As an example with the flight dataset, here is the code to persist a flights DataFrame as a table, consisting of Parquet files partitioned by the src column and bucketed by the dst and carrier columns (sorting by the id will sort by the src, dst, flightdate, and carrier, since that is what the id is made up of):
df.write.format("parquet")
.sortBy("id")
.partitionBy("src")
.bucketBy(4,"dst","carrier")
.option("path", "/user/mapr/data/flightsbkdc")
.saveAsTable("flightsbkdc")Partitioning should only be used with columns that have a limited number of values; bucketing works well when the number of unique values is large. Columns which are used often in queries and provide high selectivity are good choices for bucketing. Spark tables that are bucketed store metadata about how they are bucketed and sorted, which optimizes:
SQL
Stages
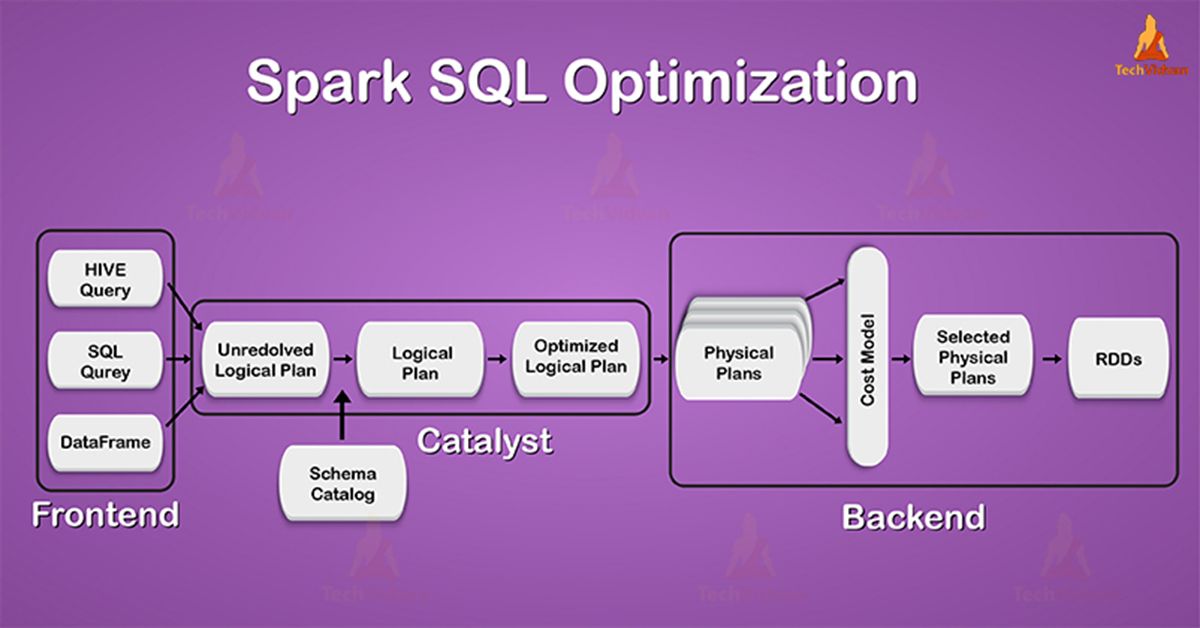
- Parser - input is declarative query (SQL, Dataset or DataFrame).
- Analyzer - use metadata catalog (persistent hive metastorage; session-local temporary view manager; cross-session global temporary view manager; session-local function registry - udf, udaf etc)
- Optimizer - use cache manager (auto replace by cached data when plan matching; cross-session; dropping/inserting tables/view invalidates all caches that depende on it; lazy evaluation). Optimizer rewrites the query plans using heuristics and cost (column pruning; outer join elimination; predicate push down; constraint propagation; constant folding; join reordering). Can inject own Optimizer and Planner Rules.
- Planner - turn logical plans to physical plans. Pick the best physical plan according to the cost (like join to broadcast hash join or to sort merge join).
- Query execution - memory manager; code generation; tungten engine
We will learn, how it allows developers to express the complex query in few lines of code, the role of catalyst optimizer in spark. At last, we will also focus on its fundamentals of working and includes phases of Spark execution flow.
Join types
- BROADCAST. Suggests that Spark use broadcast join. The join side with the hint will be broadcast regardless of autoBroadcastJoinThreshold. If both sides of the join have the broadcast hints, the one with the smaller size (based on stats) will be broadcast. The aliases for BROADCAST are BROADCASTJOIN and MAPJOIN.
- MERGE. Suggests that Spark use shuffle sort merge join. The aliases for MERGE are SHUFFLE_MERGE and MERGEJOIN.
- SHUFFLE_HASH. Suggests that Spark use shuffle hash join. If both sides have the shuffle hash hints, Spark chooses the smaller side (based on stats) as the build side.
- SHUFFLE_REPLICATE_NL Suggests that Spark use shuffle-and-replicate nested loop join.
UDF
Scalar UDF. User-Defined Functions (UDFs) are user-programmable routines that act on one row. This documentation lists the classes that are required for creating and registering UDFs. It also contains examples that demonstrate how to define and register UDFs and invoke them in Spark SQL.
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.udf
val spark = SparkSession
.builder()
.appName("Spark SQL UDF scalar example")
.getOrCreate()
// Define and register a zero-argument non-deterministic UDF
// UDF is deterministic by default, i.e. produces the same result for the same input.
val random = udf(() => Math.random())
spark.udf.register("random", random.asNondeterministic())
spark.sql("SELECT random()").show()
// +-------+
// |UDF() |
// +-------+
// |xxxxxxx|
// +-------+
// Define and register a one-argument UDF
val plusOne = udf((x: Int) => x + 1)
spark.udf.register("plusOne", plusOne)
spark.sql("SELECT plusOne(5)").show()
// +------+
// |UDF(5)|
// +------+
// | 6|
// +------+
// Define a two-argument UDF and register it with Spark in one step
spark.udf.register("strLenScala", (_: String).length + (_: Int))
spark.sql("SELECT strLenScala('test', 1)").show()
// +--------------------+
// |strLenScala(test, 1)|
// +--------------------+
// | 5|
// +--------------------+
// UDF in a WHERE clause
spark.udf.register("oneArgFilter", (n: Int) => { n > 5 })
spark.range(1, 10).createOrReplaceTempView("test")
spark.sql("SELECT * FROM test WHERE oneArgFilter(id)").show()
// +---+
// | id|
// +---+
// | 6|
// | 7|
// | 8|
// | 9|
// +---+
Aggregate UDF. User-Defined Aggregate Functions (UDAFs) are user-programmable routines that act on multiple rows at once and return a single aggregated value as a result. This documentation lists the classes that are required for creating and registering UDAFs. It also contains examples that demonstrate how to define and register UDAFs in Scala and invoke them in Spark SQL.
import org.apache.spark.sql.{Encoder, Encoders, SparkSession}
import org.apache.spark.sql.expressions.Aggregator
case class Employee(name: String, salary: Long)
case class Average(var sum: Long, var count: Long)
object MyAverage extends Aggregator[Employee, Average, Double] {
// A zero value for this aggregation. Should satisfy the property that any b + zero = b
def zero: Average = Average(0L, 0L)
// Combine two values to produce a new value. For performance, the function may modify `buffer`
// and return it instead of constructing a new object
def reduce(buffer: Average, employee: Employee): Average = {
buffer.sum += employee.salary
buffer.count += 1
buffer
}
// Merge two intermediate values
def merge(b1: Average, b2: Average): Average = {
b1.sum += b2.sum
b1.count += b2.count
b1
}
// Transform the output of the reduction
def finish(reduction: Average): Double = reduction.sum.toDouble / reduction.count
// Specifies the Encoder for the intermediate value type
def bufferEncoder: Encoder[Average] = Encoders.product
// Specifies the Encoder for the final output value type
def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
val ds = spark.read.json("examples/src/main/resources/employees.json").as[Employee]
ds.show()
// +-------+------+
// | name|salary|
// +-------+------+
// |Michael| 3000|
// | Andy| 4500|
// | Justin| 3500|
// | Berta| 4000|
// +-------+------+
// Convert the function to a `TypedColumn` and give it a name
val averageSalary = MyAverage.toColumn.name("average_salary")
val result = ds.select(averageSalary)
result.show()
// +--------------+
// |average_salary|
// +--------------+
// | 3750.0|
// +--------------+
File formats Tips
- Compression schemes
- Schema evolution and transformation of column type
- Splittable vs non-splittable compression schemes (lz4, snappy is splittable, gzip is not splittable)
- Columnar (Parquet, ORC). Efficient data skipping (column pruning, min/max stats based predicate push-down)
- Semi-structured (JSON, CSV)
- Raw text format
Tungsten
Tungsten is the codename for the umbrella project to make changes to Apache Spark’s execution engine that focuses on substantially improving the efficiency of memory and CPU for Spark applications, to push performance closer to the limits of modern hardware.
- Memory Management and Binary Processing: leveraging application semantics to manage memory explicitly and eliminate the overhead of JVM object model and garbage collection
- Cache-aware computation: algorithms and data structures to exploit memory hierarchy
- Code generation: using code generation to exploit modern compilers and CPUs
- No virtual function dispatches: this reduces multiple CPU calls which can have a profound impact on performance when dispatching billions of times.
- Intermediate data in memory vs CPU registers: Tungsten Phase 2 places intermediate data into CPU registers. This is an order of magnitudes reduction in the number of cycles to obtain data from the CPU registers instead of from memory
- Loop unrolling and SIMD: Optimize Apache Spark’s execution engine to take advantage of modern compilers and CPUs’ ability to efficiently compile and execute simple for loops (as opposed to complex function call graphs).
Structured streaming
Stream processing on Spark SQL engine. Anatomy of a Streaming word count
- Source
spark.readStream .format("kafka") .option("subscribe", "input") .load() - Transformation
.groupBy('values.cast("string") as 'key) .agg(count("*") as value) - Sink
.writeStream .format("kafka") .option("topic", "output") - Trigger - when to output. Specified as a time, eventually sports data size. No trigger means as fast as possible. OutputMode - what's output (update - output changed rows, append - output new rows only, complete - output the whole answer every time).
.trigger("1 minute") .outputMode("update") - Checkpoint - track the process of a query in persistent storage. Can be used to restart after fail.
.option("checkpointLocation", "/tmp/cp") .start()
Aggregation
// by key
events.
.groupBy("key")
.count()
// by evet time window
events
.groupBy(window("timestamp", "10 mins"))
.avg("value")
// both
events
.groupBy("key", window("timestamp", "10 mins"))
.agg(avg("value"), corr("value"))
Watermarks
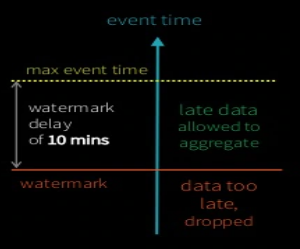
events
.withWatermark("timestamp", "10 minutes")
.groupBy(window("timestamp", "5 minutes"))
.count()
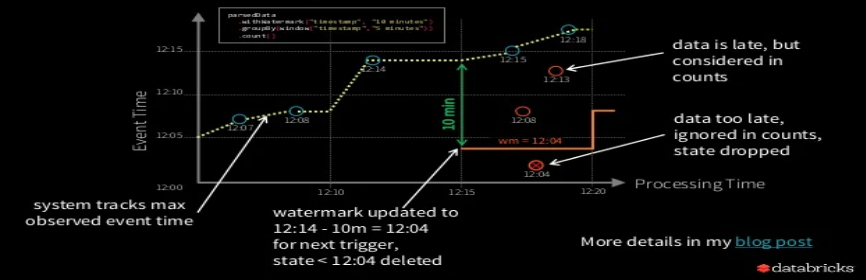
Watermarking - trade off between lateness tolerance and state size.
- Less late data processed less memory consumed
- More late data processed, more memory consumed
Drop duplicates
events
.dropDuplicates("uniqueRecordId")
// can be used with watermark
events
.withWatermark("timestamp")
.dropDuplicates("uniqueRecordId", "timestamp")
Arbitrary stateful operations
Many use cases require more complicated logic than SQL ops. Like tracking user activity on your product: user actions as input, latest user status as output.
- MapGroupsWithState
- FlatMapGroupsWithState
Related articles: