Introduction. Airflow is a platform to programmatically author, schedule and monitor workflows. Use Airflow to author workflows as Directed Acyclic Graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Workflows are expected to be mostly static or slowly changing. You can think of the structure of the tasks in your workflow as slightly more dynamic than a database structure would be. Airflow workflows are expected to look similar from a run to the next, this allows for clarity around unit of work and continuity.
High level architecture
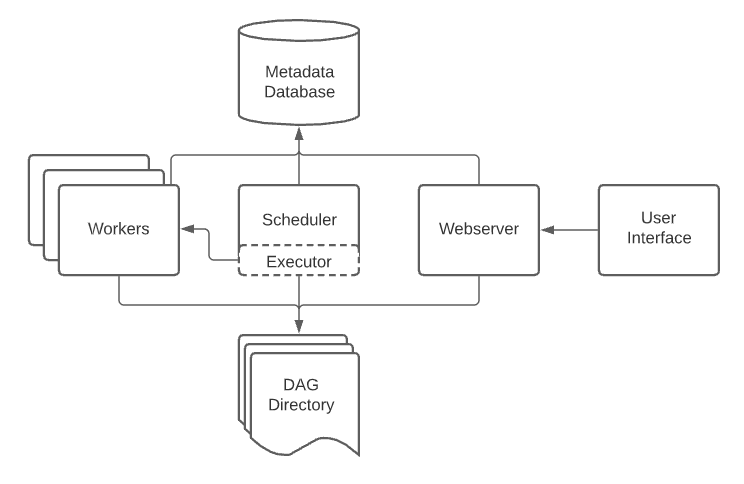
An Airflow installation generally consists of the following components:
- A scheduler, which handles both triggering scheduled workflows, and submitting Tasks to the executor to run.
- An executor, which handles running tasks. In the default Airflow installation, this runs everything inside the scheduler, but most production-suitable executors actually push task execution out to workers.
- A webserver, which presents a handy user interface to inspect, trigger and debug the behaviour of DAGs and tasks.
- A folder of DAG files, read by the scheduler and executor (and any workers the executor has)
- A metadata database, used by the scheduler, executor and webserver to store state.
Components
Airflow is a platform that lets you build and run workflows. A workflow is represented as a DAG (a Directed Acyclic Graph), and contains individual pieces of work called Tasks, arranged with dependencies and data flows taken into account.
- Operators, predefined tasks that you can string together quickly to build most parts of your DAGs.
- Sensors, a special subclass of Operators which are entirely about waiting for an external event to happen.
- A TaskFlow-decorated @task, which is a custom Python function packaged up as a Task.
#1 Simple Example
Lets look at example dag with single task:
- @dag is collections of tasks. When dag is active it executes sequence of tasks.
- @task is unit of work.
- Operator is abstraction for interact with external systems.
@dag(schedule_interval=None, start_date=datetime(2021, 1, 1), catchup=False, tags=['example'])
def example_dag_decorator(email: str = 'example@example.com'):
get_ip = GetRequestOperator(task_id='get_ip', url="http://httpbin.org/get")
@task(multiple_outputs=True)
def prepare_email(raw_json: Dict[str, Any]) -> Dict[str, str]:
external_ip = raw_json['origin']
return {
'subject': f'Server connected from {external_ip}',
'body': f'Seems like today your server executing Airflow is connected from IP {external_ip}<br>',
}
email_info = prepare_email(get_ip.output)
EmailOperator(
task_id='send_email', to=email, subject=email_info['subject'], html_content=email_info['body']
)
dag = example_dag_decorator()By default, a DAG will only run a Task when all the Tasks it depends on are successful. There are several ways of modifying this, however:
- Branching, where you can select which Task to move onto based on a condition
- Latest Only, a special form of branching that only runs on DAGs running against the present
- Depends On Past, where tasks can depend on themselves from a previous run
- Trigger Rules, which let you set the conditions under which a DAG will run a task.
#2 Dag with multiple steps
We can use "TaskFlow API" (introduced in airflow 2.x) for define tasks in function style. Here is very simple ETL pipeline using the TaskFlow API paradigm.
@dag(schedule_interval=None, start_date=datetime(2021, 1, 1), catchup=False, tags=['example'])
def tutorial_taskflow_api_etl():
@task()
def extract():
data_string = '{"1001": 301.27, "1002": 433.21, "1003": 502.22}'
order_data_dict = json.loads(data_string)
return order_data_dict
@task(multiple_outputs=True)
def transform(order_data_dict: dict):
total_order_value = 0
for value in order_data_dict.values():
total_order_value += value
return {"total_order_value": total_order_value}
@task()
def load(total_order_value: float):
print(f"Total order value is: {total_order_value:.2f}")
order_data = extract()
order_summary = transform(order_data)
load(order_summary["total_order_value"])
tutorial_etl_dag = tutorial_taskflow_api_etl()At the same time we can use old (airflow 1.x) style:
with DAG(
'tutorial',
default_args=default_args,
description='A simple tutorial DAG',
schedule_interval=timedelta(days=1),
start_date=datetime(2021, 1, 1),
catchup=False,
tags=['example'],
) as dag:
t1 = BashOperator(
task_id='print_date',
bash_command='date',
)
t2 = BashOperator(
task_id='sleep',
depends_on_past=False,
bash_command='sleep 5',
retries=3,
)
templated_command = dedent(
"""
{% for i in range(5) %}
echo "{{ ds }}"
echo "{{ macros.ds_add(ds, 7)}}"
echo "{{ params.my_param }}"
{% endfor %}
"""
)
t3 = BashOperator(
task_id='templated',
depends_on_past=False,
bash_command=templated_command,
params={'my_param': 'Parameter I passed in'},
)
t1 >> [t2, t3]#3 Sensors
Sensors are a special type of Operator that are designed to do exactly one thing - wait for something to occur. It can be time-based, or waiting for a file, or an external event, but all they do is wait until something happens, and then succeed so their downstream tasks can run.
Because they are primarily idle, Sensors have three different modes of running so you can be a bit more efficient about using them:
- poke (default): The Sensor takes up a worker slot for its entire runtime
- reschedule: The Sensor takes up a worker slot only when it is checking, and sleeps for a set duration between checks
- smart sensor: There is a single centralized version of this Sensor that batches all executions of it
Sensor is just yet another operator in your execution chain.
with airflow.DAG("file_sensor_example", default_args=default_args, schedule_interval="@once") as dag:
start_task = DummyOperator(task_id="start")
stop_task = DummyOperator(task_id="stop")
sensor_task = FileSensor(task_id="file_sensor_task", poke_interval=30, filepath="/tmp/")
gcs_file_sensor_yesterday = GoogleCloudStorageObjectSensor(task_id='gcs_file_sensor_yesterday_task',
bucket='myBucketName', object=full_path_yesterday)
gcs_file_sensor_today = GoogleCloudStorageObjectSensor(task_id='gcs_file_sensor_today_task', bucket='myBucketName',
object=full_path_today, timeout=120)
start_task >> sensor_task >> gcs_file_sensor_yesterday >> gcs_file_sensor_today >> stop_task#4 XCOM
XComs (short for “cross-communications”) are a mechanism that let Tasks talk to each other, as by default Tasks are entirely isolated and may be running on entirely different machines.
An XCom is identified by a key (essentially its name), as well as the task_id and dag_id it came from. They can have any (serializable) value, but they are only designed for small amounts of data; do not use them to pass around large values, like dataframes. But at the same time it support custom backends like S3 for store large amount of data.
XComs are explicitly “pushed” and “pulled” to/from their storage using the xcom_push and xcom_pull methods on Task Instances. Many operators will auto-push their results into an XCom key called return_value if the do_xcom_push argument is set to True (as it is by default), and @task functions do this as well.
#5 Variables
Variables are Airflow’s runtime configuration concept - a general key/value store that is global and can be queried from your tasks, and easily set via Airflow’s user interface, or bulk-uploaded as a JSON file.
Variables are global, and should only be used for overall configuration that covers the entire installation; to pass data from one Task/Operator to another, you should use XComs instead.
We also recommend that you try to keep most of your settings and configuration in your DAG files, so it can be versioned using source control; Variables are really only for values that are truly runtime-dependent.
from airflow.models import Variable
# Normal call style
foo = Variable.get("foo")
# Auto-deserializes a JSON value
bar = Variable.get("bar", deserialize_json=True)
# Returns the value of default_var (None) if the variable is not set
baz = Variable.get("baz", default_var=None)#6 Timetables
A DAG’s scheduling strategy is determined by its internal “timetable”. This timetable can be created by specifying the DAG’s schedule_interval argument, as described in DAG Run, or by passing a timetable argument directly. The timetable also dictates the data interval and the logical time of each run created for the DAG.
#7 Hooks
A Hook is a high-level interface to an external platform that lets you quickly and easily talk to them without having to write low-level code that hits their API or uses special libraries. They’re also often the building blocks that Operators are built out of.
Executors
Executors are the mechanism by which task instances get run. They have a common API and are “pluggable”, meaning you can swap executors based on your installation needs.
Airflow has support for various executors. Current used is determined by the executor option in the [core] section of the configuration file. This option should contain the name executor e.g. KubernetesExecutor if it is a core executor. If it is to load your own executor, then you should specify the full path to the module e.g. my_acme_company.executors.MyCustomExecutor.
Supported Backends:
- Sequential Executor is the only executor that can be used with sqlite since sqlite doesn't support multiple connections.
-
Debug Executor is meant as a debug tool and can be used from IDE. It is a single process executor
that queues TaskInstance and executes them by running _run_raw_task method.
if __name__ == '__main__': from airflow.utils.state import State dag.clear(dag_run_state=State.NONE) dag.run() - Local Executor runs tasks by spawning processes in a controlled fashion in different modes.
- Dask Executor allows you to run Airflow tasks in a Dask Distributed cluster.
- Celery Executor is one of the ways you can scale out the number of workers. For this to work, you need to setup a Celery backend (RabbitMQ, Redis, ...) and change your airflow.cfg to point the executor parameter to CeleryExecutor and provide the related Celery settings.
- Kubernetes Executor. The Kubernetes executor will create a new pod for every task instance.
-
CeleryKubernetes Executor allows users to run simultaneously CeleryExecutor and a KubernetesExecutor.
An executor is chosen to run a task based on the task's queue. We recommend considering
CeleryKubernetesExecutor when your use case meets:
- The number of tasks needed to be scheduled at the peak exceeds the scale that your kubernetes cluster can comfortably handle
- A relative small portion of your tasks requires runtime isolation.
- You have plenty of small tasks that can be executed on Celery workers but you also have resource-hungry tasks that will be better to run in predefined environments.
Custom Operator
Check whether a service has reached a specified rate limit threshold before continuing on with DAG.
import logging
from airflow.models import BaseOperator, SkipMixin
from airflow.utils.decorators import apply_defaults
from airflow.utils.email import send_email
from MarketoPlugin.hooks.marketo_hook import MarketoHook
class RateLimitOperator(BaseOperator, SkipMixin):
"""
Rate Limit Operator
:param service: The relevant service to check the rate limit
against. Possible values include:
- marketo
:type service: string
:param service_conn_id: The Airflow connection id used to store
the relevant service credentials.
:type service_conn_id: string
:param threshold: The threshold to trigger the operator to
skip downstram tasks. This can be either a
decimal, representing a percentage, or an
integer, representing a total request count.
:param threshold: float/integer
:param threshold_type: The type of threshold that is being used.
Possible values for this include:
- percentage
- count
By default, this is set to "percentage".
:type threshold_type: string
:param total_request_override: *(optional)* Each service will have a
default total request limit as provided
by the service's documentation. This
parameter will override this default limit
and be used as the ceiling against which
the threshold is compared.
:param total_request_override: integer
:param email_to: *(optional)* If the threshold has been hit,
send an email to the specified email(s).
Multiple email addresses may be specified
by a list.
:type email_to: string/list
"""
@apply_defaults
def __init__(self,
service,
service_conn_id,
threshold,
threshold_type='percentage',
total_request_override=False,
email_to=None,
*args,
**kwargs):
super().__init__(*args, **kwargs)
self.service = service
self.service_conn_id = service_conn_id
self.threshold = threshold
self.threshold_type = threshold_type
self.total_request_override = total_request_override
self.email_to = email_to
if self.service.lower() not in ('marketo'):
raise Exception('Specified service is not currently supported for rate limit check.')
if self.threshold_type not in ('percentage', 'count'):
raise Exception('Please choose "percentage" or "count" for threshold_type.')
def execute(self, context):
condition, current_request_count = self.service_mapper()
if condition:
self.condition_met(current_request_count)
else:
self.condition_not_met(current_request_count, context)
def condition_met(self, current_request_count):
logging.info('Rate Limit has not been exceeded.')
logging.info('Current request count is: {}'
.format(str(current_request_count)))
logging.info('Proceeding with downstream tasks...')
def condition_not_met(self, current_request_count, context):
logging.info('Rate Limit has been exceeded.')
logging.info('Current request count is: {}'
.format(str(current_request_count)))
logging.info('The specified threshold was: {}'
.format(str(self.threshold)))
logging.info('Skipping downstream tasks...')
downstream_tasks = context['task'].get_flat_relatives(upstream=False)
logging.debug("Downstream task_ids %s", downstream_tasks)
if downstream_tasks:
self.skip(context['dag_run'],
context['ti'].execution_date,
downstream_tasks)
logging.info('Sending email reminder to retry.')
if self.email_to is not None:
self.send_email(context)
logging.info("Marking task as complete.")
def service_mapper(self):
mapper = {'marketo': self.marketo_check(),
'hubspot': self.salesforce_check(),
'salesforce': self.hubspot_check()}
return mapper[self.service]
def send_email(self, context):
email_subject = "Rate Limit Hit for: {0}".format(self.service)
html_content = \
"""
The rate limit has been hit in "{0}" for the following service: {1}.
Because the rate limit operator has been used, all downstream tasks
have been skipped.
Please inspect the relevant DAG and re-run the task at a later time.
""".format(context['dag_run'], self.service)
send_email(self.email_to, email_subject, html_content)
logging.info("Email sent to: {}.".format(self.email_to))
def marketo_check(self):
token = (MarketoHook(http_conn_id=self.service_conn_id)
.run('identity/oauth/token')
.json())['access_token']
# First check the API Usage too see that we are not approaching a
# threshold based on the input parameters. 50000 requests/day is the
# limit Marketo has set.
hook = MarketoHook(http_conn_id=self.service_conn_id)
usage = hook.run('rest/v1/stats/usage.json', token=token).json()
total_current_requests = usage['result'][0]['total']
if self.threshold_type == 'percentage':
denominator = self.total_request_override if self.total_request_override else 50000
usage_percentage = total_current_requests/denominator
if usage_percentage > self.threshold:
return False, total_current_requests
else:
return True, total_current_requests
elif self.threshold_type == 'count':
if total_current_requests > self.threshold:
return False, total_current_requests
else:
return True, total_current_requests